· By Bijan Bowen
Testing OpenAI GPT o1 'Strawberry' - With Coding, Math, and Game Development
Truth be told, I don't pay much attention to the rumor mill, so my first real look into the new model(s) of OpenAI, dubbed OpenAI o1, was following the email I received today alerting me of their introduction. The email informed me that the two beta models were available in ChatGPT Plus, and gave me some other information pertaining to them.

I quickly decided to take a look at the blog post linked in the email to learn a bit more about these new "reasoning" models. A few things really stood out to me here. First, the mention of the increased difficulty in "jailbreaking" the model was very interesting to read about. Apparently in the jailbreak test, GPT-4o scored 22, while o1-preview scored 84, meaning it was far harder to jailbreak the new model to produce outputs that are deemed inappropriate. I would suppose whether or not this is good news depends on your stance on AI and your intended use cases for it. Following this, some of the test results comparing the o1 model to 4o showed incredibly substantial improvements. I do believe it would be a waste of time to regurgitate the results that can just be seen in the OpenAI blog post pertaining to the matter, so I will simply leave that linked here.

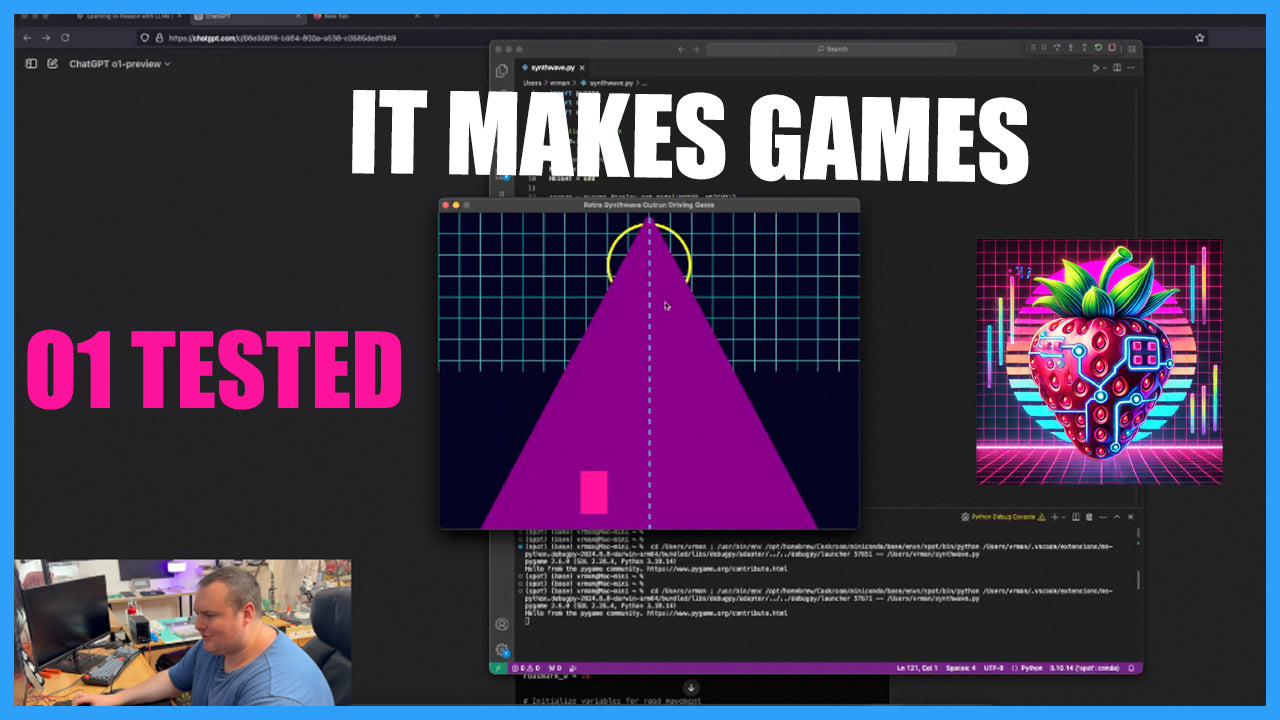
My next move was, of course, to test these new models. Given that my interest in models like these pertains to their abilities to assist in my workflow, I felt it would be a good first test to see how o1-preview did in a little Python programming task. I have recently been on a bit of a retro/synthwave kick, so I decided it would be fun to see if it could generate a retro-style, synthwave-inspired driving game. I gave it a relevant prompt stating what I wanted it to do, and instructed it to generate the game script in its entirety, without anything that would require me to procure any additional game assets external to the code it generated.

The first thing I noticed after prompting the new model was that it was explaining to me what it was doing, while it was doing it. This information was conveyed in a little text snippet below the prompt, that cycled through the model's "monologue", that is, the thought process being followed while generating the response to the user's request, which, in my case, was to make this retro-style video game.

Once the script had been generated, I was eager to get it into VSCode so that I could test it. I believe a lot of us who are familiar with using an LLM to augment our coding practices are fully aware of the stipulation that usually, the first try is not the one that works, and additional troubleshooting is usually needed before getting an entirely AI-generated script to run properly. I was very interested in seeing if this was still going to be the case, or if the o1-preview had finally managed to clear this hurdle.

While our first output was a success in that it did not throw any exceptions and fail to open, the game mechanics were lacking, to say the least. The road did not move and there was no feeling of actually going "forward". Instead of doing any troubleshooting myself, I decided to explain the issue to it and simultaneously ask it to incorporate a simple 8-bit soundtrack to accompany the game. Following this, we received our first error, pertaining to the audio being mismatched for a stereo/mono configuration. I simply copy/pasted the error message from VSCode into the model, and it correctly identified and remedied the issue. Reading through the thought process for this was very interesting and gave a good look into the model's workings.

Following this, it did produce a game with a static beep, as well as a "moving road".

To make things a bit more interesting, I asked for a soundtrack that included a scale of notes going up and down the C major chord progression, as well as a more detailed car.


When complete, it gave me a script that included an updated car, as well as an array of frequencies mapped to the C major scale to allow for the music to become a bit more "animated".

When this was completed, I went ahead and asked it to also implement the optional "Further Enhancements" it had suggested following the generation of the script, which included some particle effects, levels, and obstacles.

Finally, I brought the completed script into VSCode, launched it, and was able to see the updated game. While it wasn't a complete success, it was very interesting to see how the model was able to iterate through more and more complex versions of the game with minimal guidance and the implementation of some of its own suggestions. While this new version seemed to have lost the road, and did not show any obstacles, it did generate some particles below the car, as well as a score and levels that changed when the score threshold of +5000 was reached. The intention of the model was to have obstacles that must be avoided or the game would end, though they were not present in this script.

Overall, these new models are very interesting when factoring in the benchmark improvements displayed over 4o. While this was just a quick test that 4o would have likely been able to accomplish as well, I wanted to do something that would both test the model on more of a math/programming task, as well as get to highlight the thought process that it followed when accomplishing said tasks.
You can view the video for this article on my YouTube Channel
- #chatgpt
- #GPT 01-mini
- #GPT o1
- #GPT o1 coding
- #gpt o1 programming
- #gpt o1 programming test
- #GPT o1 tested
- #GPT o1-preview
- #gpt4o
- #o1-mini test
- #o1-preview coding
- #o1-preview game development
- #o1-preview test
- #OpenAI
- #OpenAI ChatGPT Test
- #OpenAI Strawberry
- #TechDemo
- #testing GPT o1
- #Testing GPT o1-preview