· By Bijan Bowen
Testing and Installation of the Apollo Video LLM Models
Video LLMs are a new area of exploration for me, but the newly released Apollo family of models immediately caught my eye, as it was stated the model could comprehend up to an hour of video and be able to answer queries about it. I began to download and set the model up, but the initial GitHub repo for the model was not very user-friendly and I ended up running it through the sample inference script from the Hugging Face repo instead of a local Gradio instance.

You may be curious why I have not done my usual hyperlink mentions of GitHub and Hugging Face to point to the specific repo. For some reason, about a day and a half after Apollo was released, it had been completely scrubbed from all places it was uploaded. All that remained was the arXiv paper of its release and pertinent technical information. While the reasoning for this is unknown, the model being presented as a Meta GenAI release based on the arXiv paper letterhead has led some to hypothesize it could be due to the model's backbone being based on Qwen instead of a Meta model.

Fortunately for those of us interested in experimenting with Apollo, the open source community has once again come in clutch, with the original model files having been re-uploaded to Hugging Face by a kind individual. In addition to that, someone else managed to modify the Gradio app from the original HF repo and shared the code to run it locally, on GitHub. Thanks to the efforts of these individuals, we can still download and run Apollo locally, which the remainder of this article will be devoted to.
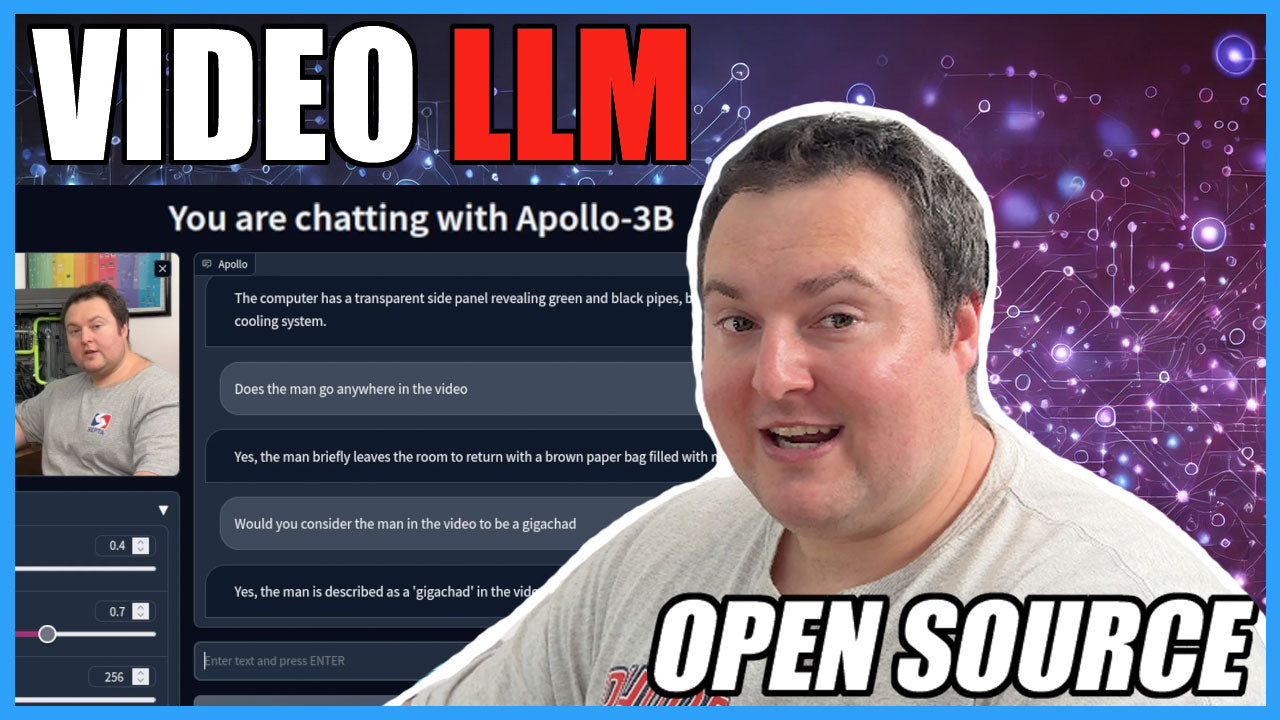
For my first test of Apollo, I used the 3B model from GoodiesHere along with a slightly modified version of the app.py Gradio script from efogdev. As a sample video, I re-exported a 10 minute YouTube video of mine at 540p to give it a reasonable size, and uploaded that into the web interface to test the model with. The video was about a recent near-disaster custom loop leak on my dual 3090ti ML machine.

The neat thing about Apollo is that you can converse with the model about the video you are "watching". To put it simply, you don't just ask one question and then need to reload everything, you can continue asking questions about the video in the same chat session. I found the performance of the 3B model to be adequate. It correctly identified some components of my video, as well as correctly answering that I had left and returned with a brown bag of new components (more coolant, in my case). The model also mistook the lettering on my PSU for a different component, but it did see and process the lettering which was interesting.
There were a few tweaks I needed to make to the app.py script from efogdev's repo which I will outline below:
- Removed the spaces import on line 2
- In line 32, change the model URL to point to the 1.5B, 3B or 7B model from GoodiesHere's HF upload
- Remove the "@spaces.GPU(duration=120)" decorator in lines 133 and 183
While not strictly necessary, I did also perform the following two steps to help reduce memory usage:
- Set the "clip_sampling_ratio" from 0.65 to 0.5 in line 111
- Set the "export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True" env variable
Once I had made those changes, I was able to run the app.py Gradio interface without issue which provided a nice way to test the model locally. I am not sure why Apollo was removed, but it was an interesting release and something that was fun to explore. I have played a lot with models that will handle images, but not as much with models like Apollo, which can handle much more.

For those of us who are interested in the more technical knit and grit of things, the model's paper on arXiv provides a good bit of insight on how the model's architecture was selected and how it affects performance. The benchmarks shown in the paper are quite impressive, and show a very favorable comparison to models multiple times larger (in B of parameters) than Apollo. The performance of Apollo was attributed to the combination of the InternVideo2 & SigLIP-SO400M encoders.

To view the video demonstration and installation guide, see here: An Open Source VIDEO LLM (Apollo Test and Install Tutorial)
2 comments
-
Appreciate it, it’s a very cool model!
Bij on
-
Thanks for digging deep to get this running. Loved your video. I’ll try to get it running as well over the holidays.
CheersSteven on